
WhiRL focuses primarly on reinforcement learning research. Some of the main topics we work on include off-policy learning, meta-learning, multi-agent reinforcement learning, Bayesian reinforcement learning, and graph-based reinforcement learning. See also a complete list of our publications.
Off-Policy Learning
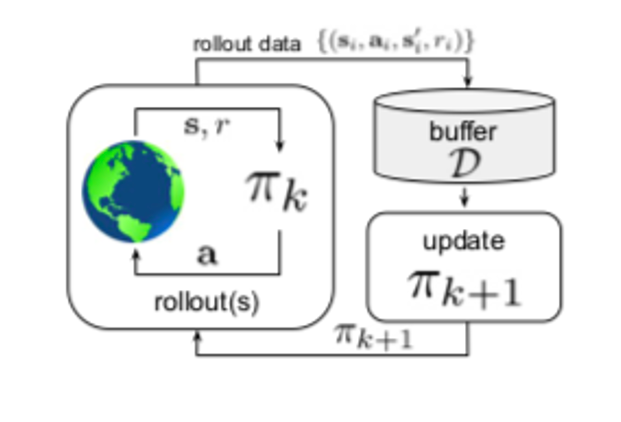
Off-policy learning enables RL agents to learn from experiences generated by policies that are different from the policy of interest. This flexibility holds the promise to greatly improve the data efficiency of RL algorithms and is key to applying RL to real-world problems. Off-policy learning, however, often leads to instability of RL algorithms, if combined with function approximation and bootstrapping, two arguably indispensable ingredients for large-scale RL applications. We propose several novel off-policy RL algorithms to address this instability issue, making use of target networks, density ratios, and differential value functions. The resulting algorithms are fully incremental and have linear per-step computation and memory complexity with respect to the number of input features, making them readily available for large-scale RL applications.
We developed a new objective for off-policy control, the first theoretically justified two-timescale off-policy actor critic algorithm, a state-of-the-art density ratio estimator for off-policy evaluation, a meta algorithm that translates any risk-neutral off-policy control method to risk-averse off-policy control method. We also revisited residual algorithms, a classical off-policy learning method, in deep RL settings which won best paper at AAMAS 2020.
Meta-Learning

Reinforcement Learning algorithms are often trained from scratch, starting with a random behaviour policy. This approach however often requires millions of environment interactions before learning to perform seemingly simple tasks such as playing a game of PacMan. One way to accelerate learning is via meta-learning, or learning to learn, where inductive biases and prior knowledge are learned from data. This has the potential to make Reinforcement Learning algorithms significantly more sample efficient at deployment, allowing them to adapt rapidly to new tasks. We are developing algorithms that allow an agent to make use of knowledge and skills it has obtained in related tasks, to learn faster and quickly infer which task it should solve. In many cases, meta-learning for fast adaptation comes down to task inference: when faced with a new task at test time, the agent has to gather experience, use it to infer the task, and then act accordingly. This insight guides a lot of our work on meta-learning.
For the episodic task adaptation setting, we developed CAVIA and VIABLE. CAVIA extends the popular MAML algorithm (Finn et al., 2017) to explicitly separate task-agnostic and task-specific information in the network. This leads to increased performance and reduces overfitting, and the learned task representation can be used for interpretation of the learned solution or downstream tasks. For the figure shown above, the Cheetah agent has to run either forward or backward, but does not know initially which is the correct direction -- it can only infer it by looking at the rewards. Our CAVIA agent only needs a few gradient updates on a single vector, or “context parameter” (which represents the task), to correctly infer the task and move in the right direction. In our work VIABLE we meta-learn a loss function that is specific to the task distribution, and helps the agent adapt even faster with the small amount of data given to it.
A particularly challenging setting is that of online adaptation, where the agent gets deployed only once and needs to perform well from the start, i.e., maximise its return while learning. Computing solutions to this problem is often intractable, but meta-learning offers a scalable way to do so. We developed a method, VariBAD, that utilises meta-learning and recent advances in approximate variational inference to learn approximately Bayes-optimal agents. In follow-up work we develop a method, HyperX which can be used on sparse reward tasks -- a setting where many existing methods break down completely.
Multi-Agent Reinforcement Learning
We work on multi-agent sequential decision making where multiple agents need to make independent and safe decisions based on their local observations through on board cameras and sensors, while still taking into account other dynamic entities capable of decision making such as humans and other agents. We use Starcraft Multi-Agent Challenge (SMAC) based on the popular real-time strategy (RTS) game StarCraft II as a benchmark environment which requires learning rich cooperative behaviours under partial observability, e.g., Focus fire ( i.e., ordering units to jointly attack and kill enemy units one after another), Kiting (i.e., making enemy units give chase while maintaining enough distance so that little or no damage is incurred ).
Some recent works include: making experience replay memory compatible with multi-agent learning via stabilising multi-agent experience replay, non linear monotonic value function factorization with QMIX, policy gradient method with multi-agent credit assignment counterfactual multi-agent policy gradients, coordination graph based value function factorization deep coordination graphs, role-based multi-agent learning method which effectively discovers roles based on joint action space decomposition RODE, and learning on non monotonic tasks with monotonic value functions via weighted learning weighted-QMIX, multi-task learning UneVEn, and ensemble learning MAVEN.
Bayesian Reinforcement Learning
Reinforcement learning as inference recasts the problem of finding an optimal policy as one of approximate inference. In doing so, it leverages powerful tools from variational inference that can advance our algorithms in reinforcement learning, often by introducing additional regularisation into our objectives. Bayesian reinforcement learning characterises the uncertainty in the MDP by inferring a posterior distribution over an unknown quantity, for example the reward function and transition kernel in model-based Bayesian RL or the value function in model-free Bayesian RL. As well as being able to incorporate prior knowledge of the MDP into the learning process, a Bayesian approach can optimally solve the exploration/exploitation dilemma. Developing approximate inference methods that render the inference tractable is a key challenge in Bayesian RL.
In VIREL, we investigated the reinforcement learning as inference problem from a theoretical perspective, offering a solution to the bias introduced by the additional regularisation. For the multi-agent setting, our paper MAVEN exploits the reinforcement learning as inference framework to derive a tractable variational bound on an intractable mutual information objective, which is necessary to encourage learning of diverse joint behaviours. It is well understood that Bayes-adaptive MDPs offer an elegant solution to the exploration-exploitation problem, however exact inference is intractable for all but the simplest of settings. To overcome this issue, we developed VariBAD which performs approximate inference using meta-learning to infer a tractable posterior over the space of MDPs. In Exploration in Approximate Hyper-State Space for Meta Reinforcement Learning, we build on the meta learning approach introduced in VariBAD by recognising that exploration during meta-training is essential to good performance when rewards are sparse. Our proposed solution, HyperX, uses novel reward bonuses for meta-training to explore in approximate hyper-state space and can solve sparse reward tasks for which existing methods fail.
Graph-Based Reinforcement Learning
In the last couple of years, graph neural networks have become a subject of intensive research in deep RL. We work on multitask reinforcement learning in incompatible environments, i.e., environments with mismatching state and action space dimensions, where the state space can be represented as a graph. We employ graph neural networks to accommodate the challenge of arbitrary-sized inputs and outputs. The directions of future research in this area include search for novel architectures and useful inductive biases, developing better interpretability methods, scaling the models and studying the interplay between GNN approximations and RL algorithms. Some relevant papers include Boolean SAT solvers and Incompatible Multitask RL for Continuous Control.